Image-to-video (I2V) generation is a challenging task that requires transforming a static image into a dynamic video according to a text prompt. For a long time, it has been a challenging task that demands both subject consistency and text semantic alignment. Moreover, existing I2V generators require expensive training on large video datasets. To address this issue, we propose PiLife (\emph{Prompt image to Life}), a novel training-free I2V framework that leverages a pre-trained text-to-image diffusion model. PiLife can generate videos that are coherent with a given image and aligned with the semantics of a given text, which mainly consists of three components: (i) A motion-aware diffusion inversion module that embeds motion semantics into the inverted images as the initial frames; (ii) A motion-aware noise initialization module that employs a motion text attention map to modulate the diffusion process and adjust the motion intensity of different regions with spatial noise; (iii) A probabilistic cross-frame attention module that leverages a geometric distribution to randomly sample a frame and compute attention with it, thereby enhancing the motion diversity. Experiments show that PiLife significantly outperforms the training-free baselines, and is comparable or even superior to some training-based I2V methods. Our code will be publicly available.
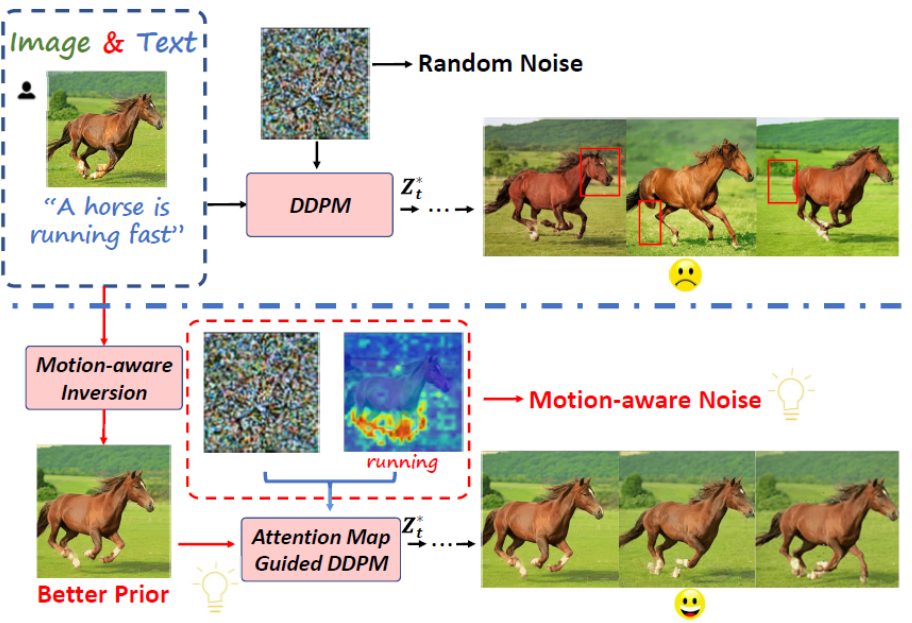
We conclude two factors that affect image-to-video generation qualities. First, image input misalignment with the diffusion model's distribution. Second, the noise variance across frames uniformly distributed across the entire image.
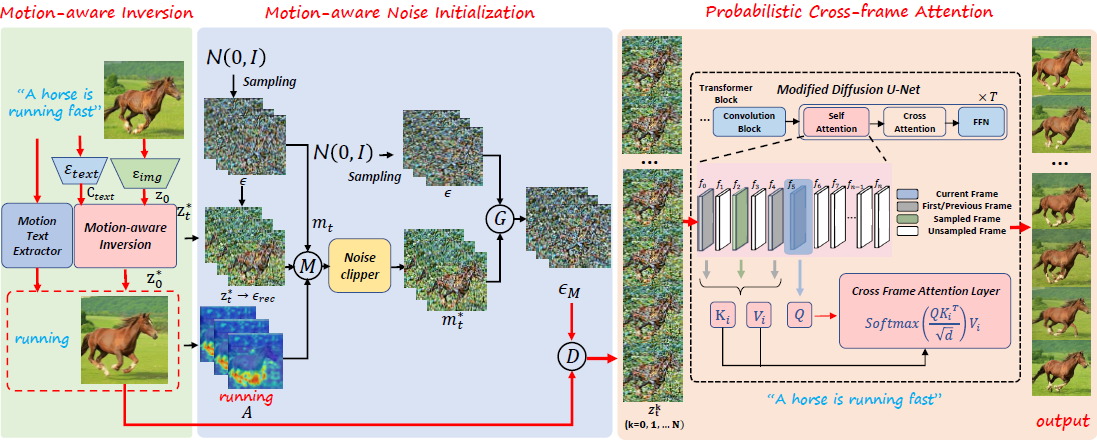
Our PiLife framework consists of three main modules. (1) The motion-aware diffusion inversion module processes the input text and image to obtain the initial frame with motion information. (2) The motion-aware noise initialization module generates the noise with motion features and initial latent code. (3) The probabilistic cross-frame attention layer replaces the self-attention layer to enhance motion features.
  |
  |
  |
  |
| "Rainstar fly through the sky" | "The spring is flow with raining." | "Thunder is lighting in the sky" | "A handsome boy is talking something" |
  |
 (1).gif)  |
 (1).gif)  |
.gif)  |
| "A bear is dancing happily in the forest." | "A beautiful girl is playing the piano." | "A horse is running fast." | "Water is flowing." |
 (1).gif)  |
.gif)  |
  |
  |
| "A man is playing the guitar" | "Fire is burning." | "A speedboat is surfing on the sea." | "A cyber style of rain out of the window" |

